Law of large numbers
In probability theory, the law of large numbers (LLN) is a mathematical law that states that the average of the results obtained from a large number of independent random samples converges to the true value, if it exists.
The LLN is important because it guarantees stable long-term results for the averages of some random events.
The LLN only applies to the average of the results obtained from repeated trials and claims that this average converges to the expected value; it does not claim that the sum of n results gets close to the expected value times n as n increases.
Today, the LLN is used in many fields including statistics, probability theory, economics, and insurance.
[3] For example, a single roll of a six-sided die produces one of the numbers 1, 2, 3, 4, 5, or 6, each with equal probability.
These methods are a broad class of computational algorithms that rely on repeated random sampling to obtain numerical results.
[4] The average of the results obtained from a large number of trials may fail to converge in some cases.
[7] One way to generate the Cauchy-distributed example is where the random numbers equal the tangent of an angle uniformly distributed between −90° and +90°.
The Italian mathematician Gerolamo Cardano (1501–1576) stated without proof that the accuracies of empirical statistics tend to improve with the number of trials.
A special form of the LLN (for a binary random variable) was first proved by Jacob Bernoulli.
[10][3] It took him over 20 years to develop a sufficiently rigorous mathematical proof which was published in his Ars Conjectandi (The Art of Conjecturing) in 1713.
In 1837, S. D. Poisson further described it under the name "la loi des grands nombres" ("the law of large numbers").
After Bernoulli and Poisson published their efforts, other mathematicians also contributed to refinement of the law, including Chebyshev,[13] Markov, Borel, Cantelli, Kolmogorov and Khinchin.
[3] Markov showed that the law can apply to a random variable that does not have a finite variance under some other weaker assumption, and Khinchin showed in 1929 that if the series consists of independent identically distributed random variables, it suffices that the expected value exists for the weak law of large numbers to be true.
One is called the "weak" law and the other the "strong" law, in reference to two different modes of convergence of the cumulative sample means to the expected value; in particular, as explained below, the strong form implies the weak.
Lebesgue integrable random variables with expected value E(X1) = E(X2) = ... = μ, both versions of the law state that the sample average
The weak law of large numbers (also called Khinchin's law) states that given a collection of independent and identically distributed (iid) samples from a random variable with finite mean, the sample mean converges in probability to the expected value[20] That is, for any positive number ε,
Interpreting this result, the weak law states that for any nonzero margin specified (ε), no matter how small, with a sufficiently large sample there will be a very high probability that the average of the observations will be close to the expected value; that is, within the margin.
For example, the variance may be different for each random variable in the series, keeping the expected value constant.
In fact, Chebyshev's proof works so long as the variance of the average of the first n values goes to zero as n goes to infinity.
What this means is that, as the number of trials n goes to infinity, the probability that the average of the observations converges to the expected value, is equal to one.
[17] The strong law of large numbers can itself be seen as a special case of the pointwise ergodic theorem.
This view justifies the intuitive interpretation of the expected value (for Lebesgue integration only) of a random variable when sampled repeatedly as the "long-term average".
Borel's law of large numbers, named after Émile Borel, states that if an experiment is repeated a large number of times, independently under identical conditions, then the proportion of times that any specified event is expected to occur approximately equals the probability of the event's occurrence on any particular trial; the larger the number of repetitions, the better the approximation tends to be.
This theorem makes rigorous the intuitive notion of probability as the expected long-run relative frequency of an event's occurrence.
The weak law of large numbers states: This proof uses the assumption of finite variance
The limit eitμ is the characteristic function of the constant random variable μ, and hence by the Lévy continuity theorem,
Therefore, This shows that the sample mean converges in probability to the derivative of the characteristic function at the origin, as long as the latter exists.
[1] By applying Borel's law of large numbers, one could easily obtain the probability mass function.
[34] Using the Monte Carlo method and the LLN, we can see that as the number of samples increases, the numerical value gets closer to 0.4180233.


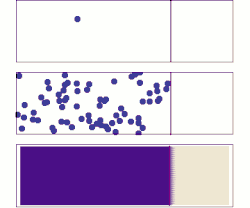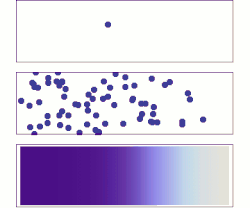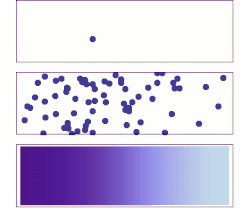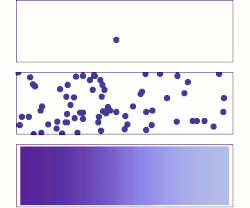
- Top: With a single molecule, the motion appears to be quite random.
- Middle: With more molecules, there is clearly a trend where the solute fills the container more and more uniformly, but there are also random fluctuations.
- Bottom: With an enormous number of solute molecules (too many to see), the randomness is essentially gone: The solute appears to move smoothly and systematically from high-concentration areas to low-concentration areas. In realistic situations, chemists can describe diffusion as a deterministic macroscopic phenomenon (see Fick's laws ), despite its underlying random nature.